ASPL Agent V1: Adaptive Self-improvement Learning for ML Library Development
March 01, 2025
More details can be found in our ICML 2025 paper. We open source the algorithm with the agentic system here.
ML library development using ASPLs
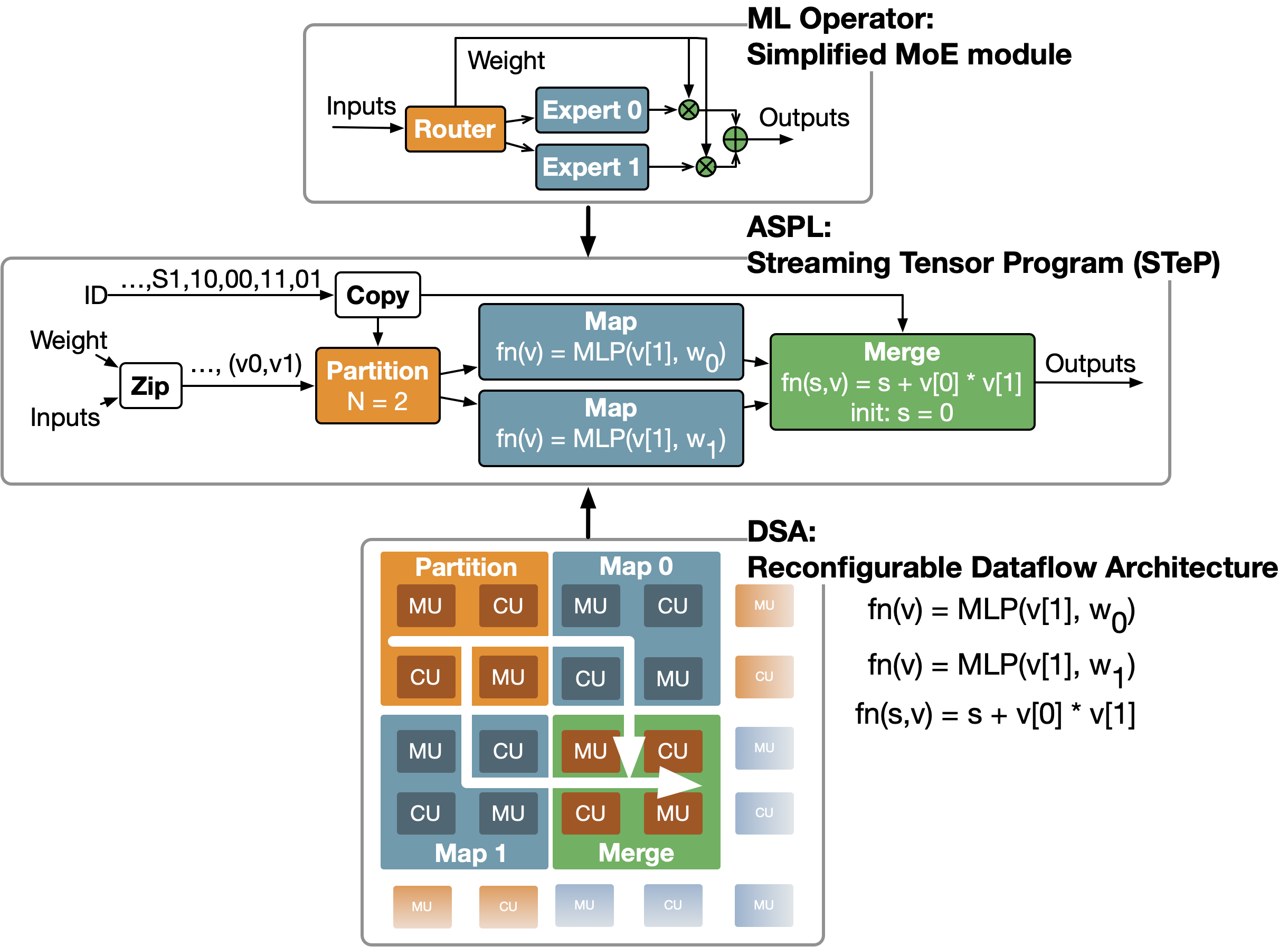
ML libraries, such as cuDNN and MIOpen, provide high-performance implementation of the operators in ML frameworks such as PyTorch and Jax. They are key to efficient ML systems. ML libraries are often written in architecture-specific programming languages (ASPLs) that target domain-specific architectures (DSAs). Figure 1 shows an example of ML library development.
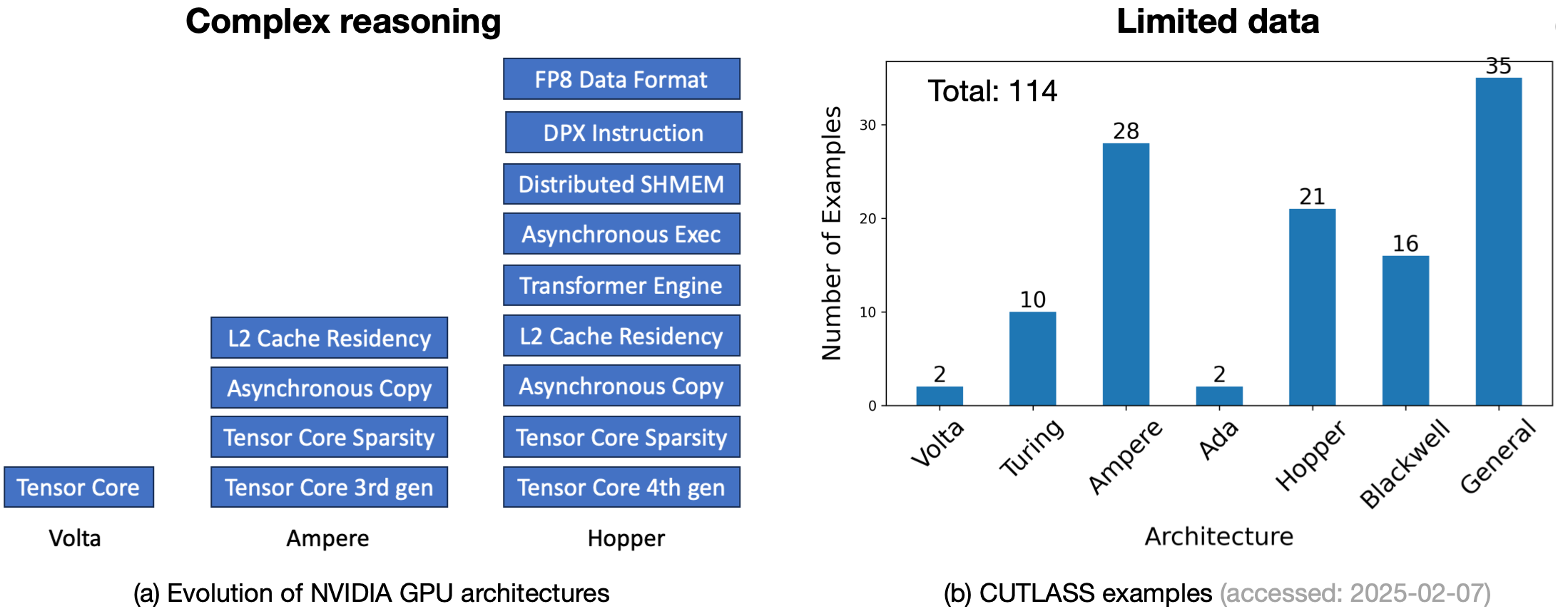
However, writing these high-performance ML libraries is challenging because it needs expert knowledge of ML algorithms and the ASPL. This process requires complex reasoning to compose high-level ML model components (“operators”) with low-level hardware primitives. Meanwhile, ASPLs are updated per generation of DSA, so there is limited data as shown in Figure 2.
Adaptive Self-improvement LLM Agentic System
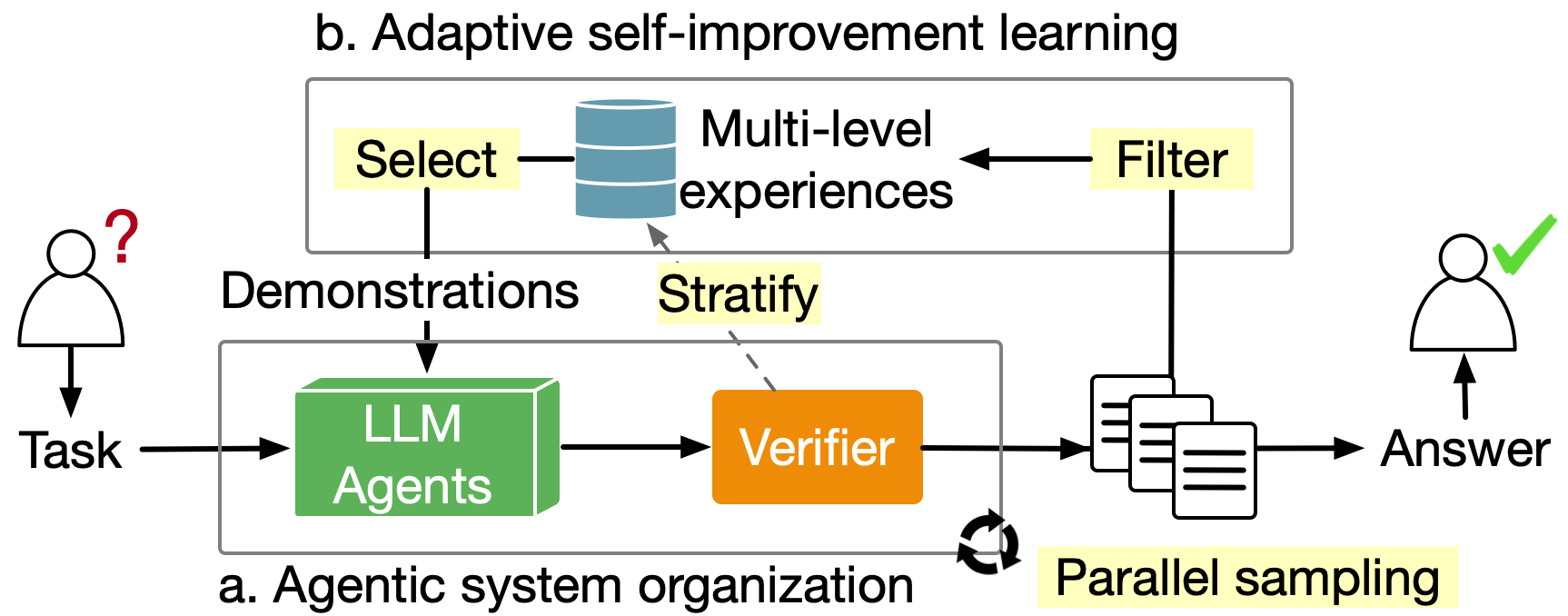
Large language models (LLMs) have shed light on solving complex programming tasks. This work explores LLMs’ potential for automating ML library development. We propose an adaptive self-improvement learning algorithm integrated with an agentic system organization that orchestrates LLMs with different capabilities. Figure 3 shows the system diagram.
We find that adaptive self-improvement can elevate weaker base models above powerful reasoning models; self-improved DeepSeek-V3 completes 3.9x more tasks than a single DeepSeek-V3 and outperforms OpenAI-o1. Adaptively selecting a smaller number of high-quality demonstrations can outperform larger quantities of lower-quality demonstrations. Interestingly, Claude 3.5 Sonnet unexpectedly surpasses other models, including self-improved DeepSeek-V3.
Adaptive self-improvement learning evolves LLM agents with data generated by themselves. As shown in Figure 4, LLM agents accumulate experience through sampling on each task, with experiences becoming more hard-earned as success rates decrease. Our algorithm prioritizes hard-earned experiences as demonstrations. When these hard-earned experiences are used up, the algorithm adaptively increases the number of demonstrations by mixing experiences earned from less challenging tasks. Such experience stratification and adaptive selection is inspired by curriculum learning1. As a byproduct, the algorithm adaptively increases test-time compute on challenging tasks until they are finished or the data is used up.

The agentic system organization is ASPL-specific. We choose Streaming Tensor Programs (STeP)2 as the target ASPL for library generation. STeP is an emerging ASPL designed for next-generation reconfigurable dataflow architectures3, a family of DSAs for AI. As shown in Figure 1, we build an LLM system that can generate the STeP program that implements the PyTorch program on top.
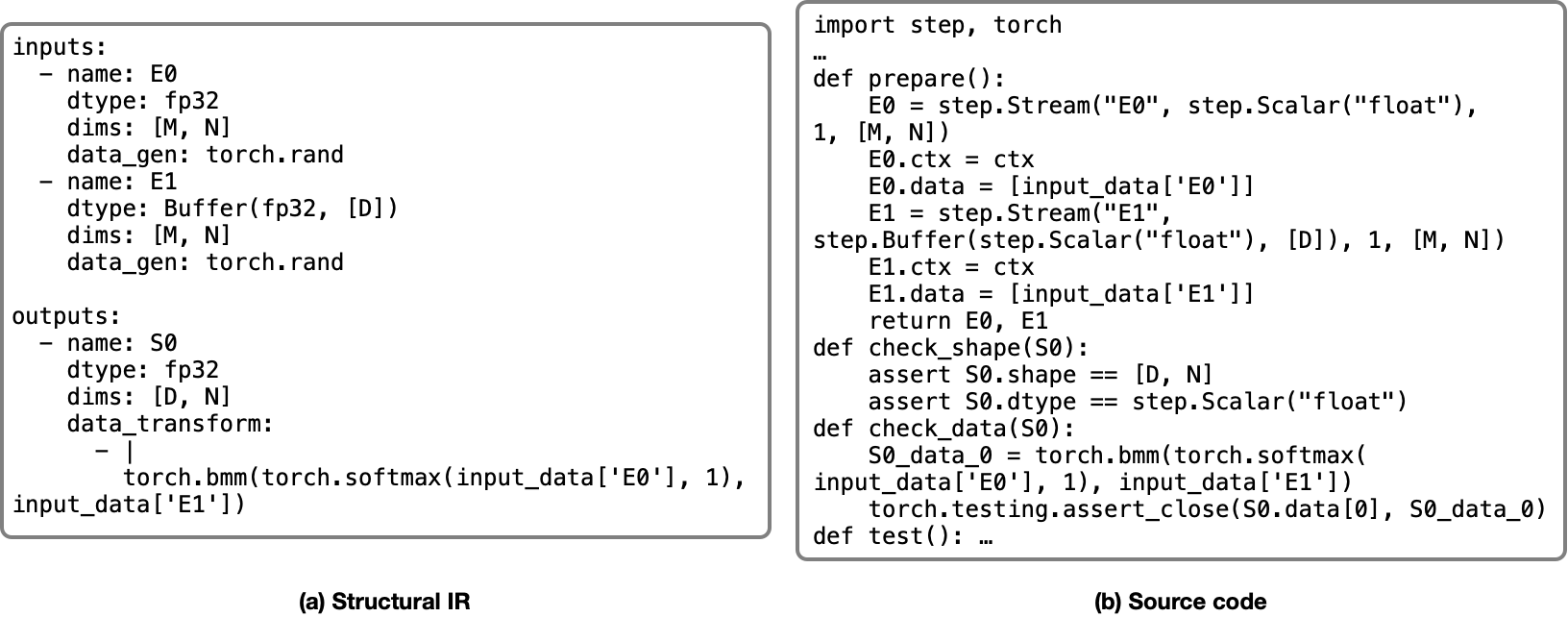
As shown in Figure 5, we design two agents, a proposer, which generates a candidate STeP implementation, and a guardian that checks and corrects the affine type error. The verifier wraps the STeP implementation with testing logic and feeds it to two checkers for (i) functional correctness and (ii) affine type constraint. Structural intermediate representation (IR) encodes necessary information using a data serialization language. This distinguishes our system from coding agents that directly deal with source code as shown in Figure 6.

Key results
We benchmarked 8 groups of ML operators for a common LLM layer and collected 26 tasks in total. We select frontier models from four providers: Claude 3.5 Sonnet from Anthropic, o1 and GPT-4o from OpenAI, Llama 3.1-405B from Meta, and DeepSeek-V3 from DeepSeek. DeepSeek-V3 was just announced in December 2024. OpenAI o1 implements a test-time compute strategy for general reasoning tasks and is 6 times more expensive than GPT-4o per token. All four other models are base models without a predefined test-time compute strategy.
Here we share three interesting findings:
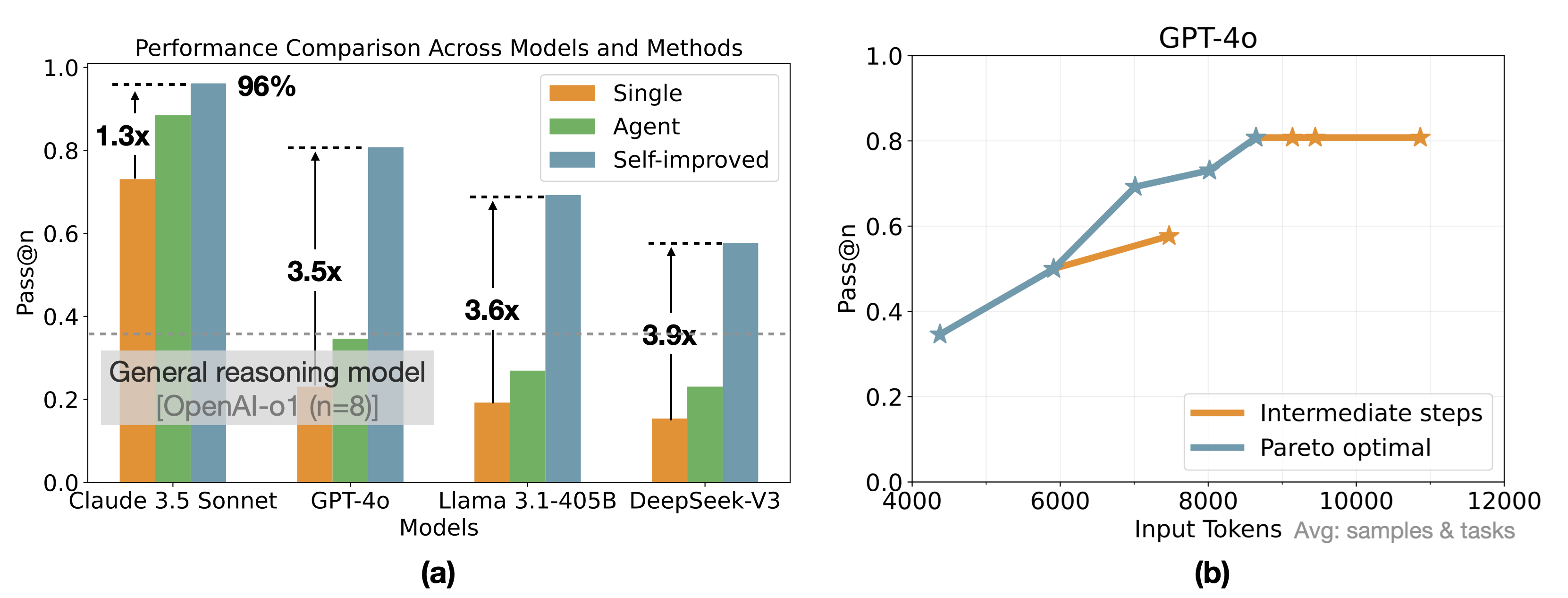
- Adaptive self-improvement learning can augment relatively weak base models to surpass a powerful general reasoning model. As shown in Figure 7(a), self-improved DeepSeek-V3 outperforms OpenAI-o1, successfully implementing 57.7% of operators compared to OpenAI-o1’s 38.5%.
- Claude 3.5 Sonnet is surprisingly better than other models although they have similar scores on common coding benchmarks (e.g. on HumanEval-Mul all models achieve around 80% Pass@1 as in Table 6 of DeepSeek-V3 technical report4). As shown in Figure 7(a), even single Claude 3.5 Sonnet is better than self-improved DeepSeek-V3.
- Experience stratification can improve data efficiency. As shown in Figure 7(b), a smaller number of input tokens can sometimes outperform a larger number due to the higher quality of experiences.
Impact
Our approach not only produces a self-improving agentic system to assist humans but also generates high-quality ML operators that can be leveraged by other systems. By enabling users without extensive ASPL expertise to construct efficient ML operators, this advancement could democratize access to ML development tools and reduce the technical barriers to entry. As stronger models emerge, such as DeepSeek-R1 and OpenAI o3-mini, our tasks can offer a good benchmark to test their complex reasoning with limited data.
The paper is selected as one of the Best Paper Awards at the DL4C Workshop @ ICLR 2025. The paper is also accepted as posters for ICLR 2025 Workshop on Reasoning and Planning for Large Language Models and 2025 MLSys Young Professionals Symposium.
References
- Bengio, Y., Louradour, J., Collobert, R. and Weston, J., 2009, June. Curriculum learning. In Proceedings of the 26th annual international conference on machine learning (pp. 41-48). ↑
- Sohn, G., Gyurgyik, C., Zhang, G., Velury, S., Mure, P., Zhang, N. and Olukotun, K., 2024. Streaming tensor programs: A programming abstraction for streaming dataflow accelerators. In ASPLOS Young Architect Workshop (YArch).↑
- Prabhakar, R., Zhang, Y., Koeplinger, D., Feldman, M., Zhao, T., Hadjis, S., Pedram, A., Kozyrakis, C. and Olukotun, K., 2017, June. Plasticine: A Reconfigurable Architecture For Parallel Paterns. In Proceedings of the 44th Annual International Symposium on Computer Architecture (pp. 389-402).↑
- Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C. and Dai, D., 2024. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437.↑