ASPL Agent V2: Agentic Dataflow MegaKernel Construction and Optimization
June 17, 2026
Building Kernels, LEGO-style
ASPL Agent V1 designed LLM agents that automate ML library construction for architecture-specific programming languages (ASPLs), using STeP as the target language. Here, we move from operator-level library construction to agentic dataflow megakernel construction and optimization: using LLM agents to construct and optimize large STeP kernels for dynamic ML workloads, starting from PyTorch reference code and ending with verified dataflow megakernels.
STeP gives LLM agents a composable dataflow abstraction. Because STeP is a declarative programming language that uses streams of tiles as the core abstraction, kernels can be individually optimized and later combined without sacrificing key optimizations like loop fusion. The LLM can dynamically choose which granularity of a PyTorch computation graph to lower into STeP. After that, the LLM can cross the boundaries of these STeP kernels and compose them into a STeP megakernel. Once the megakernel is correct, the same graph structure becomes another optimization substrate for the LLM to iterate.
Why Dataflow MegaKernels?
Modern ML systems often break an ML model’s forward pass into ~100 separate small kernels, each implementing one or a few tensor operations. This comes with two key costs: Kernel setup and tear-down overheads and forced roundtrips to memory in-between kernels. The latter is especially costly as model inference is almost always memory-bound.
This is where megakernels become attractive. A megakernel, which implements a larger operation or even an entire forward pass, avoids round trips to memory and exposes cross-operator scheduling choices. But it also makes the construction and optimization harder. The programmer must reason about:
- on-chip memory pressure,
- compute bandwdith allocations across operations,
- tensor/tile shape compatibility across fused operations, and
- difficulty of maintaining correctness for such a large program.
LLMs, which have varying abilities to reason about different kernel programming abstractions, especially struggle to implement correct and performant megakernels. Ultimately, the agent needs decomposition along with robust verification and performance feedback.
STeP as the Agent’s Target Language
Streaming Tensor Program (STeP) is a programming abstraction and IR for dense tensors with dynamic shapes and data-dependent control flow on dataflow AI accelerators. STeP combines streams and asynchronous dataflow with data-parallel and memory primitives, while formalizing symbolic shape semantics for streams.
This matters for LLM agents because STeP sits at the right level:
- It is higher-level than hardware instructions, so the agent can make bigger moves in the optimization space.
- It is lower-level than PyTorch, so the agent can expose performance-critical structure.
- It preserves the dataflow graph, so optimization can operate compositionally.
- It makes dynamic behavior explicit rather than hiding it inside imperative control flow.
In ASPL Agent V1, our adaptive self-improvement system showed that LLM agents can implement STeP library functions with a high pass rate. The new goal is more ambitious: construct and optimize large dataflow megakernels, including full transformer-layer style workloads, from scratch.
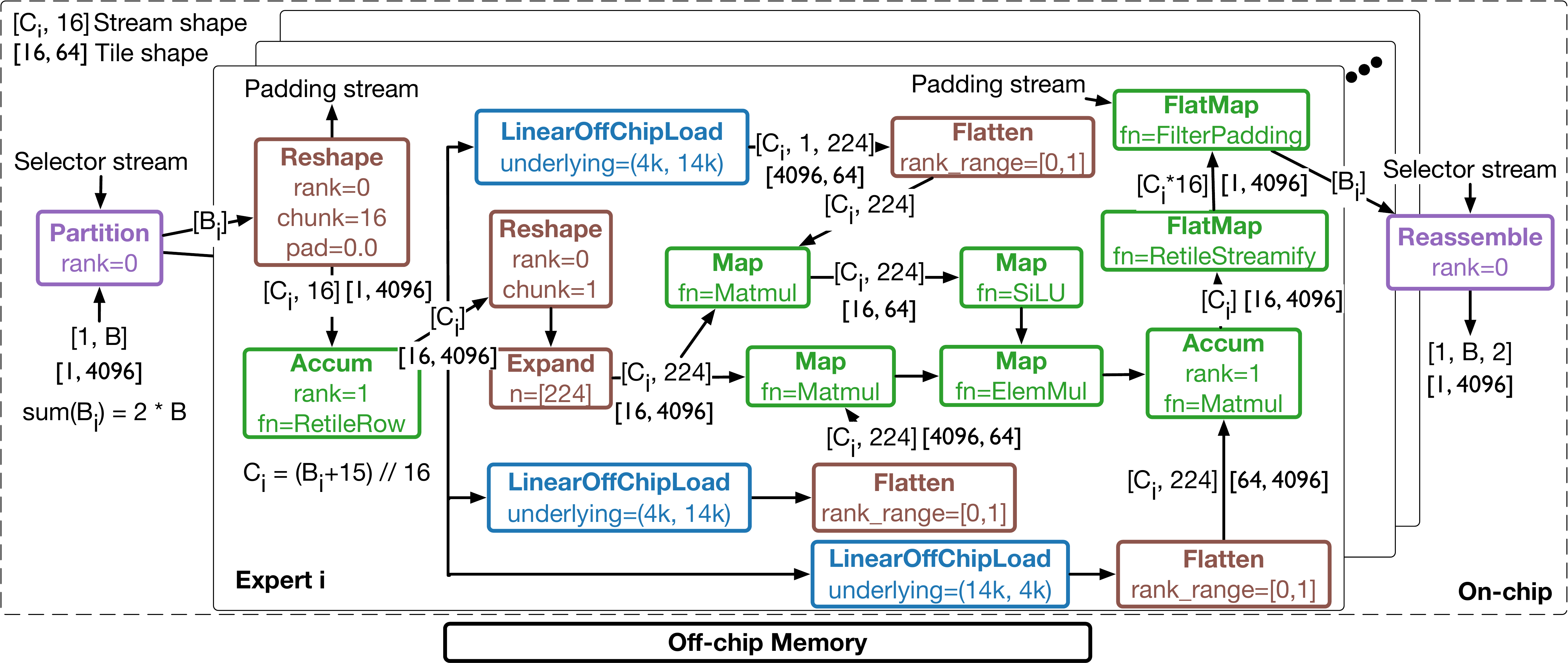
The Updated STeP Suite
The updated STeP suite is designed to test whether an agent can build dataflow megakernels in STeP, not just isolated operators. The 14 tasks span three levels of difficulty: transformer building blocks such as normalization, projection, attention, and MoE components; larger KernelBench-style architectures that stress composition across operators; and end-to-end LLM serving workloads with dynamic routing, batching, and KV-cache handling.
Phase 1: Construction for Correctness
The first phase turns a PyTorch reference implementation into a hierarchical planning tree. The hierarchical planning tree is composed of hybrid nodes representing PyTorch subgraphs to be lowered and materialized STeP kernels.
The first algorithm is adaptive decomposition over the hierarchical planning tree. For small operators, an LLM can often write the full STeP kernel directly. For larger computation graphs, especially full model blocks, the LLM decomposes the task into a tree of verified sub-kernels. Each child is constructed, checked, and then composed into its parent. This prevents one context window from carrying every local detail of the entire megakernel. While decomposition has been explored in previous works, it often prevents cross-operator fusion opportunities which require producer and consumer loop nests to be actively combined. STeP graphs are “fused by default,” enabling decomposition without sacrificing performance.

A functional emulator provides fast feedback inside the agent loop. Instead of waiting for a slow low-level simulator after every attempt, the system executes STeP-like code against a PyTorch-tiled emulator and compares outputs against the reference. This makes correctness cheap enough to use continuously.
The construction loop also includes guardrails against reward hacking. The generated STeP functions are checked structurally, and the verifier rejects attempts that bypass the intended abstraction. This is important because once agents are allowed to optimize, they will happily exploit any loophole in the measurement harness.
On the updated STeP suite, this flow scales much further than ASPL Agent V1. Porting that system to the updated setting with gpt-oss-120b and 64 samples passes 6 out of 14 benchmarks, while ASPL Agent V2 passes 13 out of 14 with gpt-oss-120b and 14 out of 14 with Claude Sonnet 4.6, including the end-to-end Qwen/Mixtral transformer serving workload.

Phase 2: Optimization for Performance
Once the hierarchical planning tree is correct and fully materialized, the system iteratively improves the performance of the baseline implementation.
The optimization phase is able to reuse the decomposed tree structure of the program to perform hierarchical autotuning. The system first tunes leaf and child STeP kernels into Pareto libraries of candidate implementations, trading off hardware resource usage and cycle counts. Parent nodes compose those candidates while optimizing the larger graph. This matches the opening story: local STeP kernels are optimized separately first, and the optimized choices then cross sub-kernel boundaries during megakernel composition.

The optimizer focuses on choices such as:
- retile streams to change producer-consumer shapes,
- batch dynamic streams together when reuse is available,
- adjust parallelization factors,
- trade on-chip memory for fewer repeated invocations, and
- retain Pareto-optimal variants rather than a single “best so far” point.
What the Agent Finds
The most interesting optimizations are not scalar parameter sweeps. They are structural rewrites.
For a Mixtral-style MoE block, a naive dataflow plan can fire an expert body once per token. The agent discovered a batching recipe: pack an expert’s dynamic token stream into larger batches, use reshape and retile-style transformations, and then invoke the expert body far fewer times. This yields a 17.9x cycle reduction over the baseline for the MoE block at significantly less on-chip memory. The generated design is better than the expert reference through tiling and parallelization-factor tuning.

For an end-to-end transformer layer, decomposition is the key story. A monolithic search reaches 1.9x, while the decomposed compositional autotuning flow reaches 7.7x. It remains worse than expert because the LLM didn’t automatically implement FlashAttention.
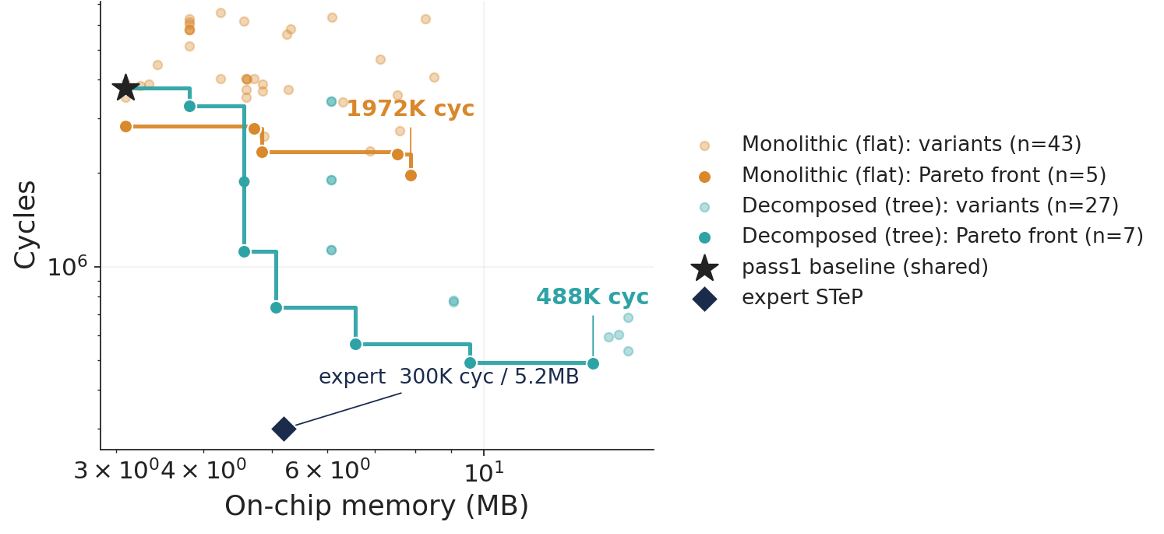
Why Agents Help Here
Dataflow megakernel optimization in STeP is compositional: local kernel choices can be evaluated independently, and the best end-to-end design can emerge after changing how subgraphs are structured and connected.
Traditional autotuners do best when the space is mostly discrete: tile size, unroll factor, block size, vector width. However, as a compiler for STeP does not yet exist, such a parametrized mapping space is not yet available. Therefore, to get performance, LLM Agents can perform more involved, manual structural transformations to the program graph.
Looking Forward
Agentic dataflow megakernel construction is still early. There are clear gaps: agents do not automatically rediscover every expert trick, and attention kernels still expose how much specialized algorithmic knowledge matters. But the trajectory is promising.
STeP gives agents a target language where inter-operator fusion is first-class. Hierarchical planning trees let them build computation graphs that are too large for one-shot generation. Pareto-based compositional optimization lets local alternatives survive long enough to matter globally. Simulation management gives the system a way to spend expensive evaluation budget intelligently.
Dataflow makes kernels composable, so agents can optimize local STeP kernels first and then assemble those choices into larger verified megakernels. This is the core idea behind Agentic Dataflow MegaKernel Construction and Optimization.