AccelOpt+Fixer for Triton on H100
January 26, 2026
The code for AccelOpt is open-source and available on GitHub: https://github.com/zhang677/AccelOpt. This blog records new results beyond our MLSys 2026 paper. Accelopt is a follow-up to this work. Please refer to this blog for the basic introduction of AccelOpt and its application to NKI.
What about GPU?
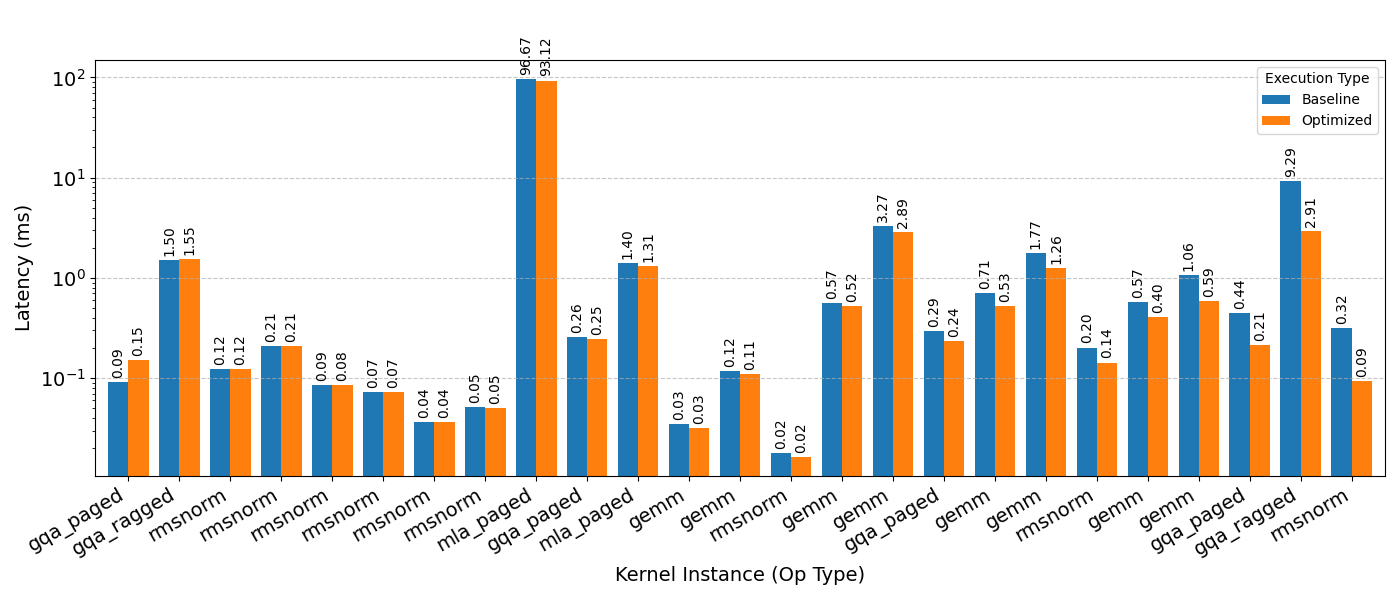
AccelOpt is a hardware-agnostic framework. To demonstrate its efficacy, we evaluated its performance on the H100 SXM5 platform using 24 of the FlashInfer-Bench best Triton baselines (as of December 23, 2025). Utilizing the gpt-oss-120b model, AccelOpt discovered significant kernel enhancements, achieving up to a 6.78x speedup. Here are some of the generated kernels. We are currently collaborating with the FlashInfer-Bench team to integrate these optimized kernels into the public benchmark.
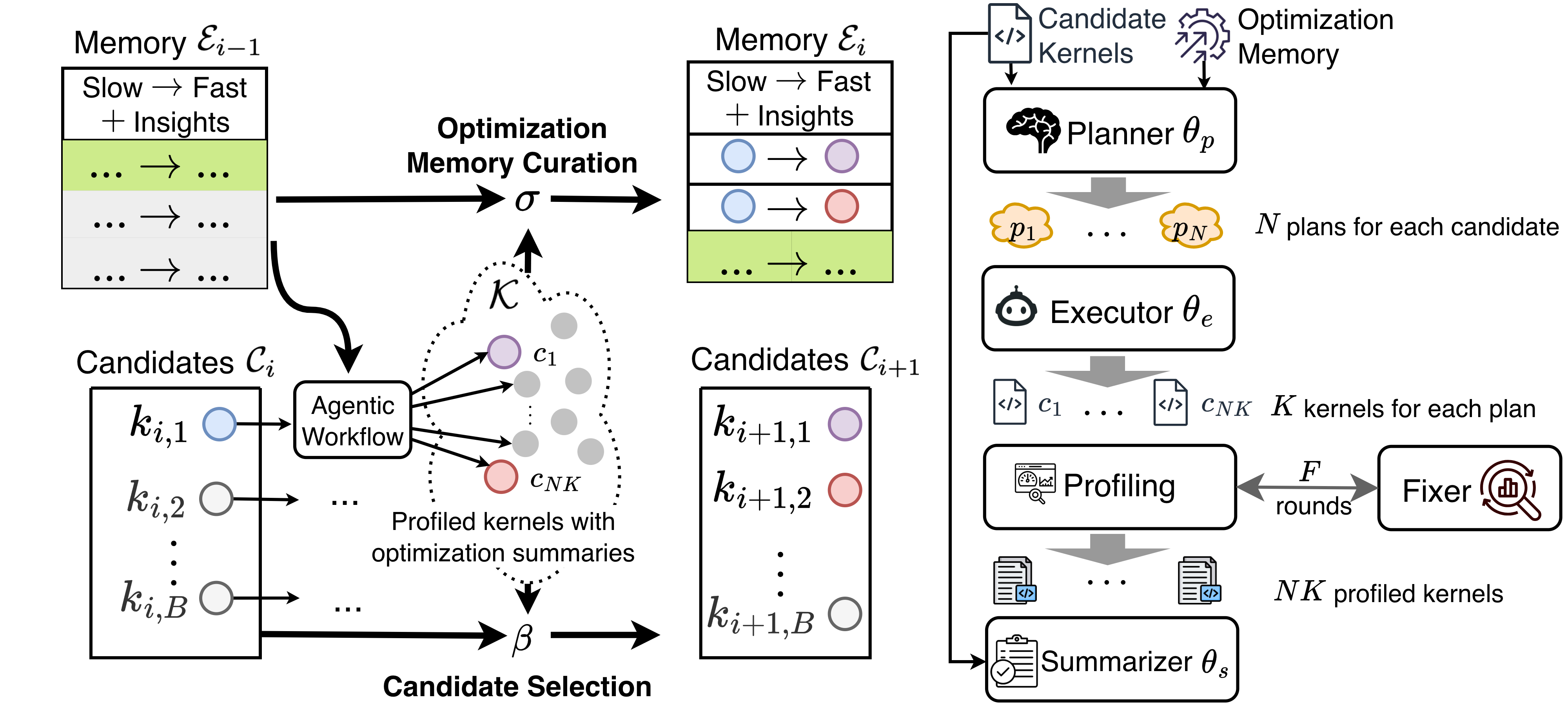
Can Iterative Refinement (Fixer) Boost Self-Improvement?
Iterative refinement extends the limits of self-improvement by fixing syntactic bugs in potentially fast kernels. Our implementation adds a “fixer” agent after the executor; for every sampled kernel, the fixer takes the failed code and the error log to generate a fixed version. The fixer repeats this process until the fixed kernel is correct or the allocated budget is reached.
Iterative refinement is useful because LLMs often commit syntactic errors despite explicit prompt constraints. Typical errors involve unsupported behaviors like slice indexing on local accumulators and manual shared memory management. These mistakes might stem from the LLM conflating Triton’s syntax with that of similar languages.
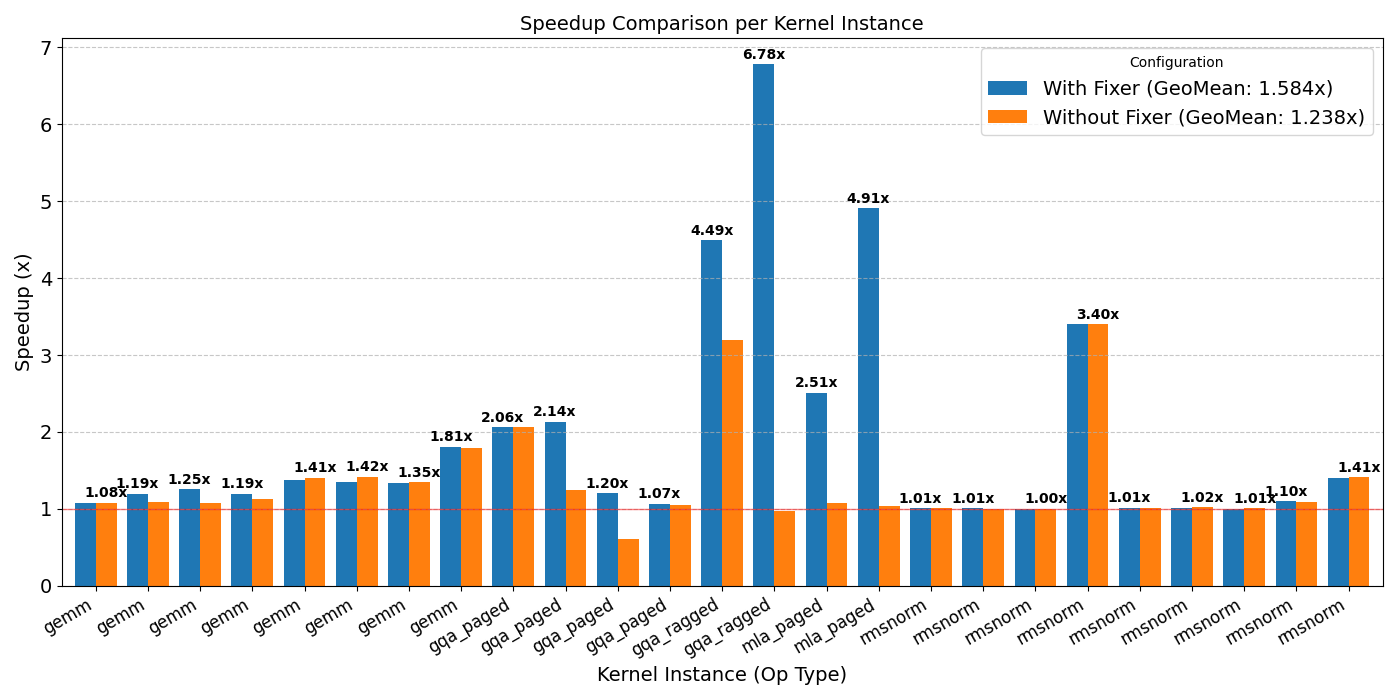
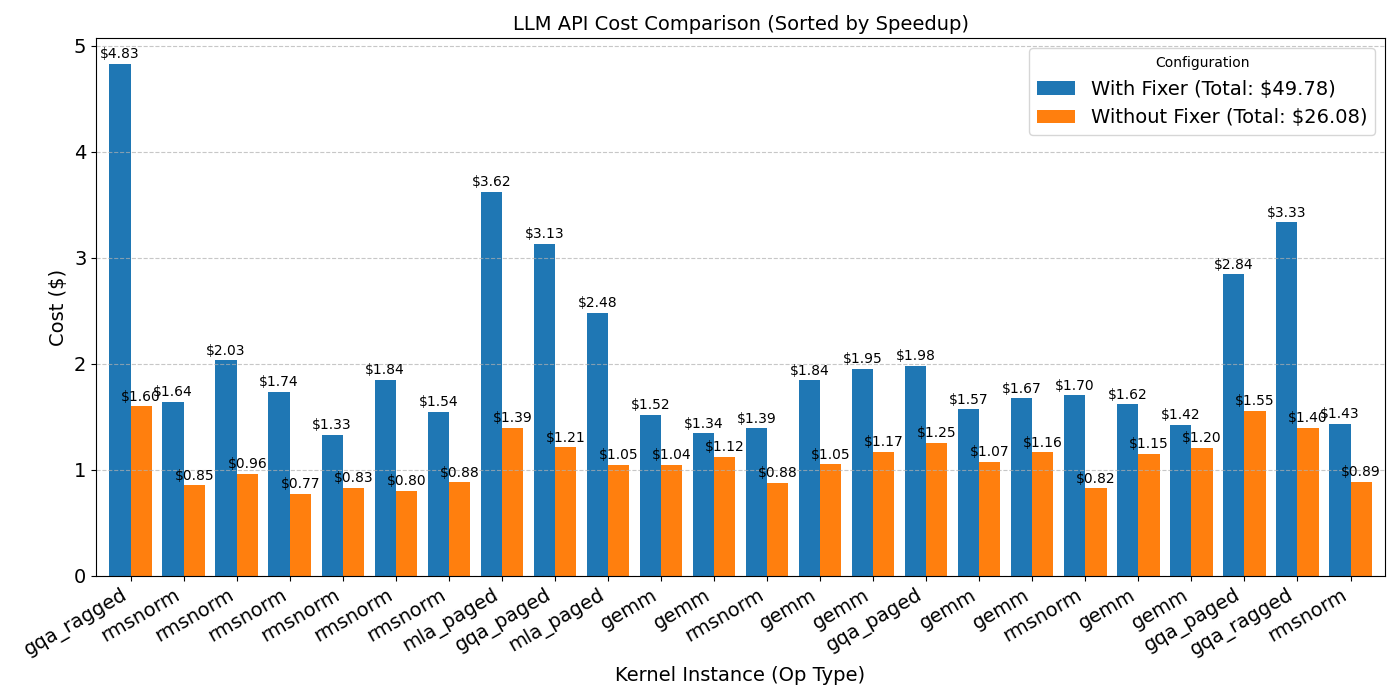
Iterative refinement is particularly effective for complex kernels like GQA and MLA, which are more prone to errors due to their code density. Built on top of AccelOpt, iterative refinement achieves another 32.8% speedup at a total cost of only $23.70. It is worth noting that with AccelOpt, kernel optimization can be incredibly affordable, delivering over a 5x speedup for less than $5.
How far is AccelOpt from Human Experts?
Triton Attention. We compared AccelOpt (B=2, N=4, K=2, F=5) on H100 SXM5 against FlashInfer across 8 attention workloads of FlashInfer-Bench. The best AccelOpt configuration achieved an average of 0.59x the performance of FlashInfer and 1.5x at best on GQA_Paged_Decode. We also observed that better base models (from gpt-oss-120b to gemini-3-flash) can yield a 1.61x speedup and doubling the number of iterations can lead to an additional 1.18x speedup.
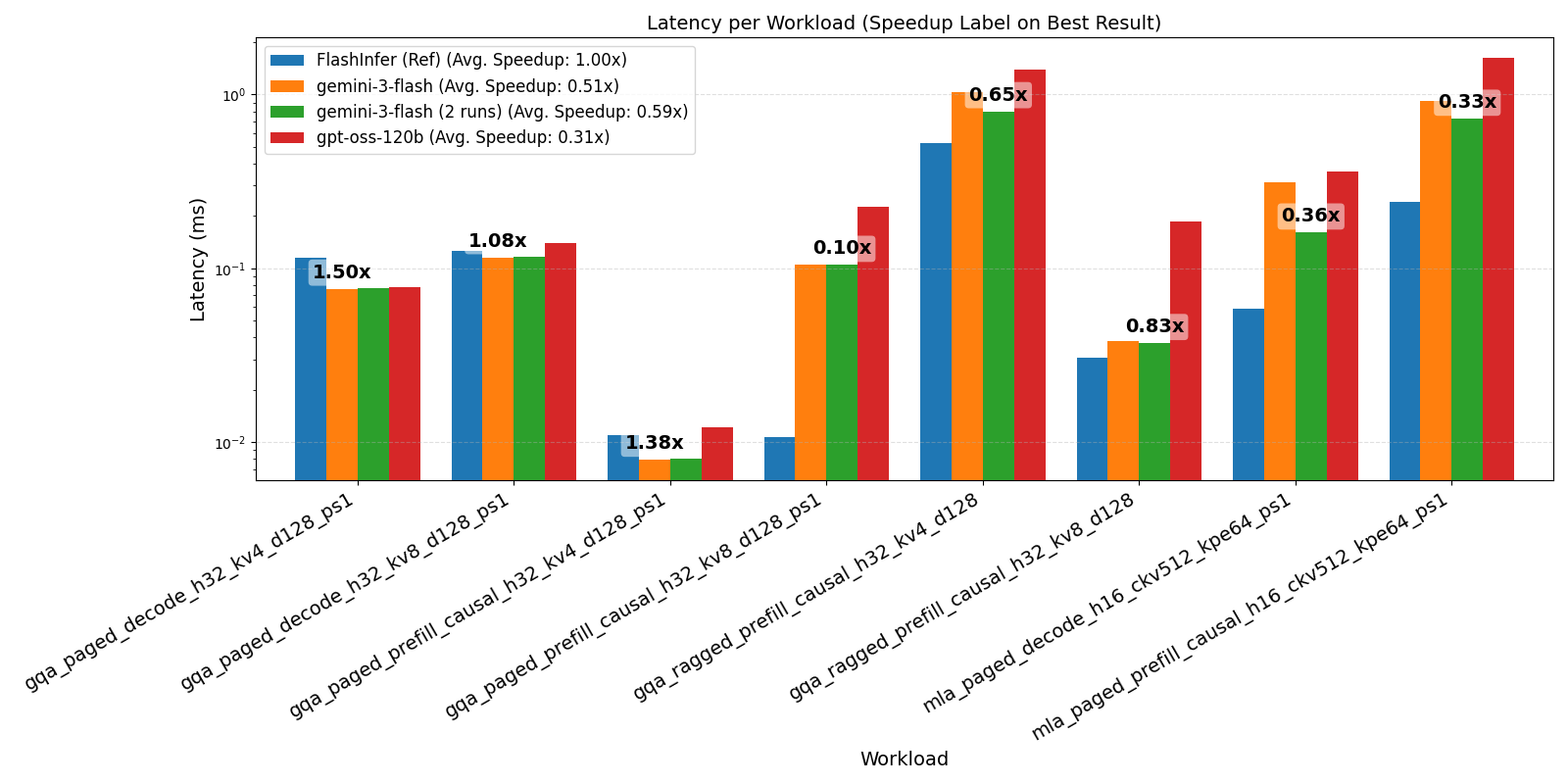
These results demonstrate that AccelOpt can exceed expert-level performance in Triton. This stems from AccelOpt’s scalability: human experts optimize a handful of kernels sequentially, while AccelOpt can explore many in parallel. We uploaded all the kernels mentioned above here.
Acknowledgement
This work was a collaborative effort across several teams. I would like to thank our collaborators from Stanford University, AWS Neuron Science Team, and the University of Toronto: Shaowei Zhu, Anjiang Wei, Zhenyu Song, Allen Nie, Zhen Jia, Nandita Vijaykumar, Yida Wang, and Kunle Olukotun. I’m also grateful to Yixin Dong from the FlashInfer-Bench team for his insights and collaboration.